If you have not done it yet, you still have some times.
05:00
Learning objectives
Understand the fundamentals of R and its development environment.
Get introduced to Quarto and learn how to create dynamic, reproducible reports.
Convert a Quarto document into an interactive sharable report.
Be able to clean and transforming data with R
Schedule
Time
Topic
9:00 - 9:30
Welcome & Overview of R and Quarto
9:30 - 10:30
Basics functions used in importing and cleaning datasets
10:30 - 10:45
Break
10:45 - 12:00
Transforming data for analysis using participants’ examples
11:45 - 12:00
Lunch Break
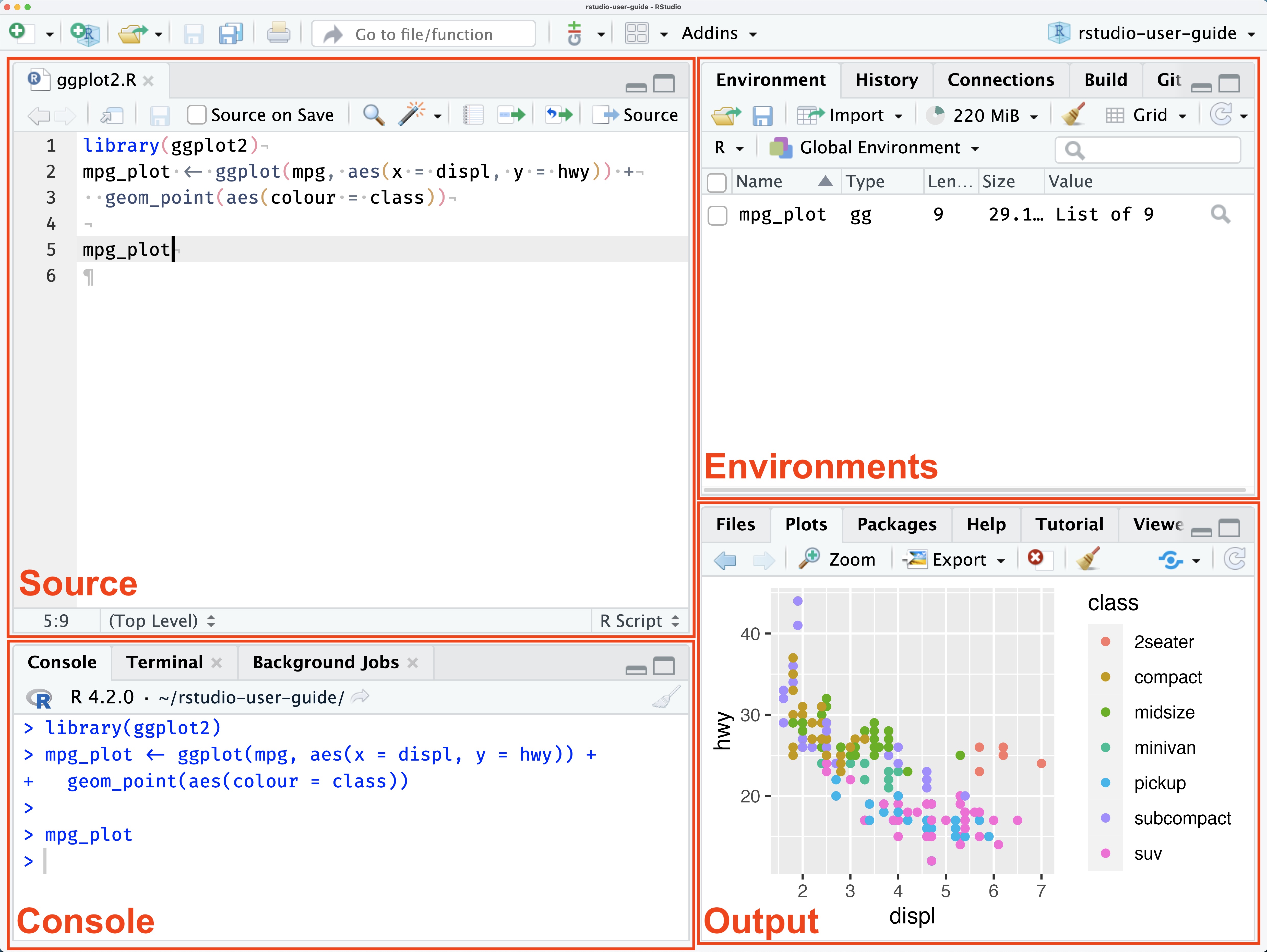
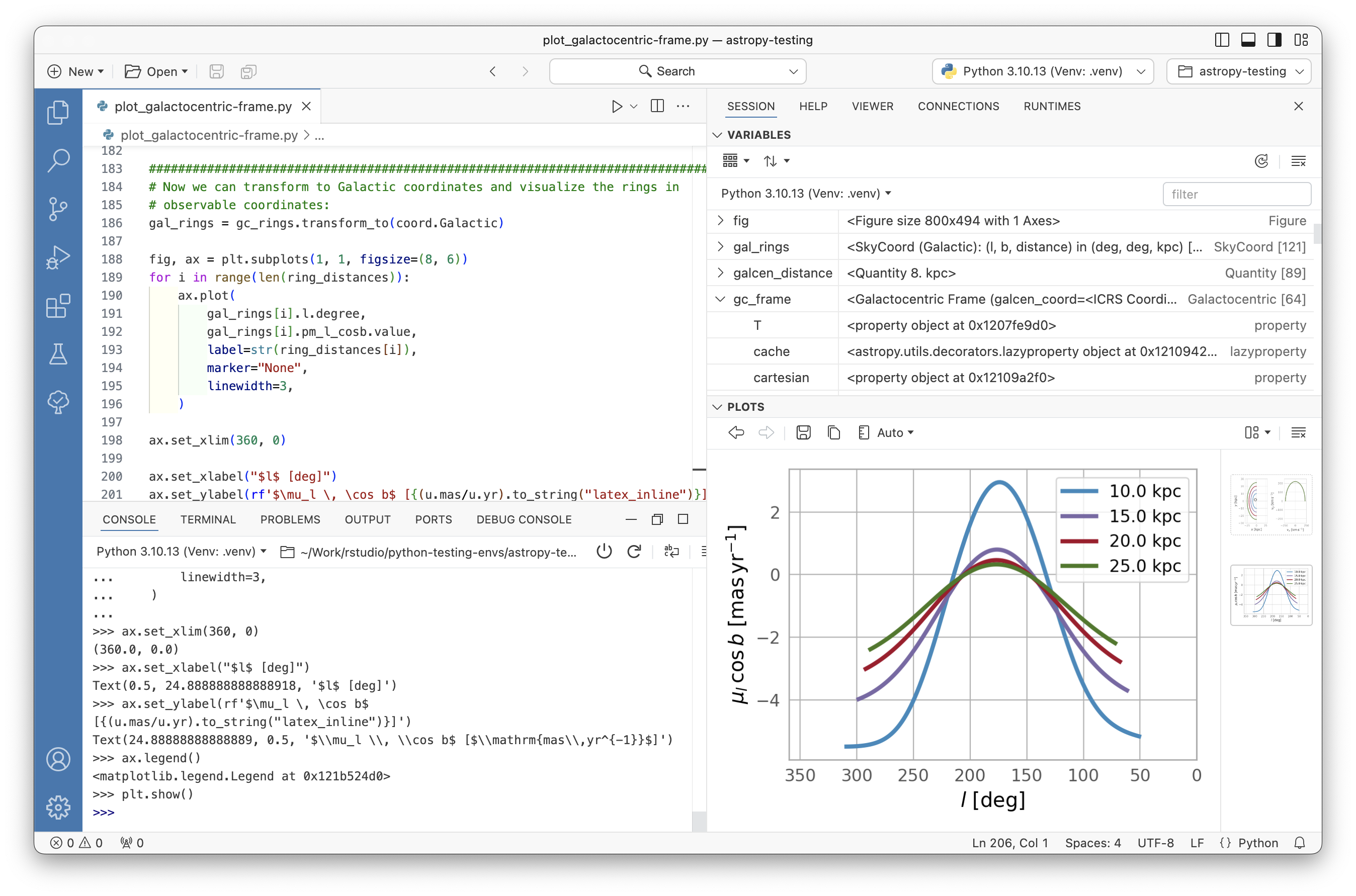
Working with R
Install R alone would be enough for analysis
Working with R before was very difficult due to lacking of supporting features of the development environment like code completion, syntax highlighting, project management, etc.
RStudio IDE released in 2013 and Positron IDE released in 2024 makes working with R much easier
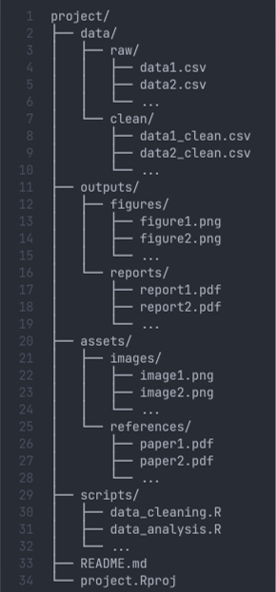
Working directory
A data analysis project must be organized in a folder structure
If you work with Rstudio, you should create a Rstudio project
It helps addressing a lot of stress regarding setwd(), getwd()
If you work with Positron, you don’t need to create a project
In STATA or SPSS, you work with .dta and .sav file, which is assumed as your project, but also a data file
For R and general programming language, a project and a data file is two different concepts
Import and export data
Use of the rio package to flexibly import() and export() many types of files
Use of the here package to locate files relative to an R project root - to prevent complications from file paths that are specific to one computer
Specific import scenarios, such as:
Specific Excel sheets
Messy headers and skipping rows
From Google sheets
From data posted to websites
With APIs
Importing the most recent file
Manual data entry
R-specific file types such as RDS and RData
Exporting/saving files and plots
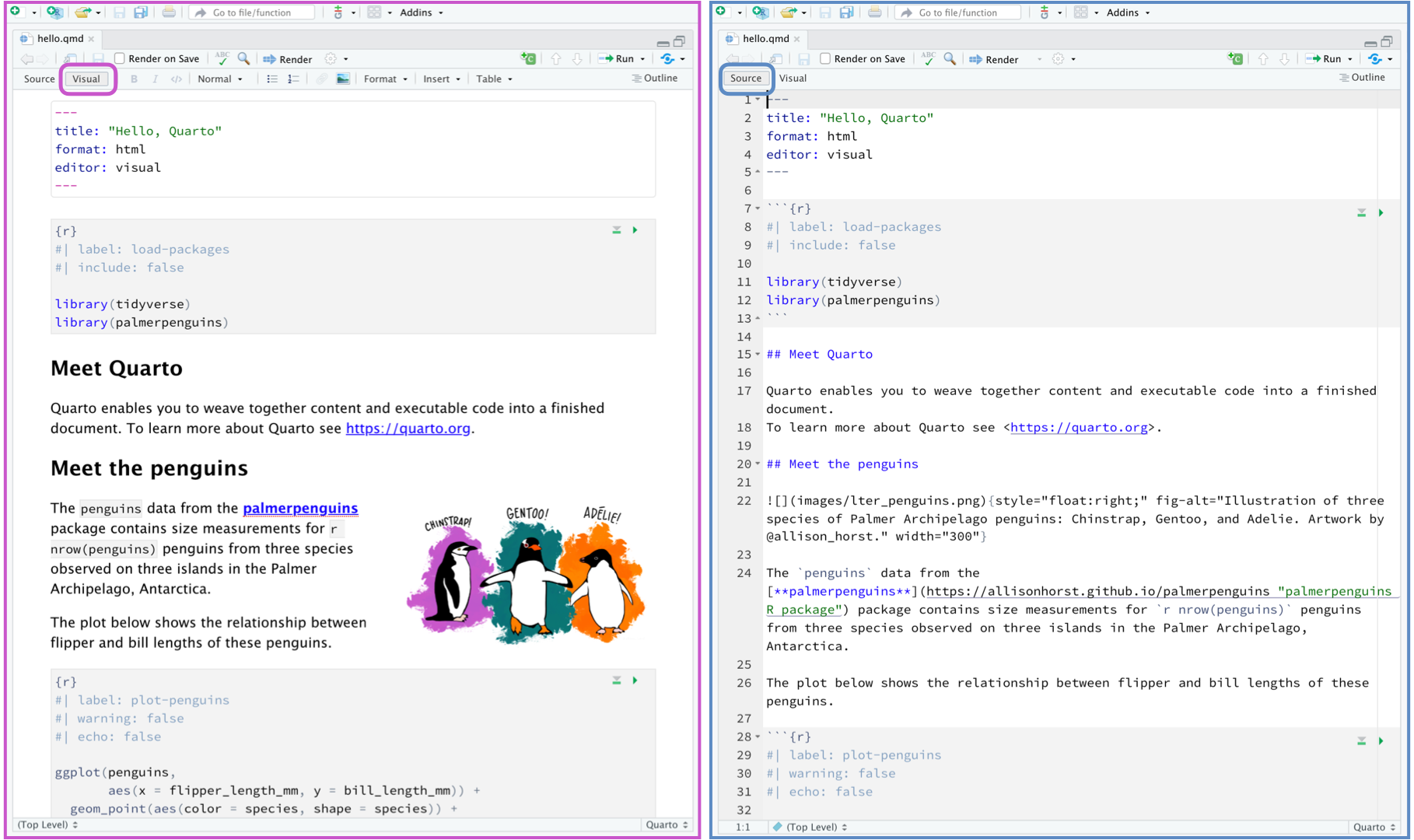
Import and export data
import() function is versatile to import any kind of data, while here() function is used to construct the file path.
The use of here() is to create a relative file path, avoiding cross OS system, different computers problems.
data <-import(here("data", "Linet_14.04.2025.dta"))
DON’T
data <-import("D:/04 EXPERIMENTS/gothenburg_ws/data/Linet_14.04.2025.dta")
R allows you to work with multple datasets at the same time
You can export safely your cleaned data into a .Rds file, share with colleagues and re-use but it is not a common practice
WHY? Because file size is usually large. In the era of big data, it is not optimal. Also having no cleaned data file forces you to write a reproducible code
Basic R syntax
Pipes
Used to chain (connect) several functions together